Before some days I’d written an answer on HN where I explained as simply as possible how a forward and a reverse proxy is working and what is the difference between them. In this article I’m going to extend this answer a bit to make it a full post and clarify some things even more.
Forward and reverse proxies is an important concept that a lot of technical people aren’t familiar with. HTTP Proxying is a process of forwarding (HTTP) requests from one server to the other. So when an HTTP client issues a request to the server, the request will pass through the proxy server and be forwarded to the destination server (called the origin server). This explanation is true both for forward and reverse proxying.
Forward Proxy
A forward proxy is used when an HTTP Client (i.e a browser) wants to access resources in the internet but isn’t allowed to connect directly to the public internet so instead uses the proxy.
Usually companies don’t allow unrestricted access to the internet from their internal network. Thus the internal users would need to use a proxy to access the internet. This is the concept of the forward proxy. What happens is that when an internal user want to access an internet resource (i.e www.google.com) her client (i.e browser) will ask a specific server (the proxy server) for that resource. The client needs to be configured properly with the address of the proxy server.
So instead of http://www.google.com the browser will access http://proxy.company.com/?url=www.google.com and the proxy will fetch the results and return them to you. If the browser wants to access https://www.google.com without a configured proxy server it will get a network error.
Here’s an image that explains this:
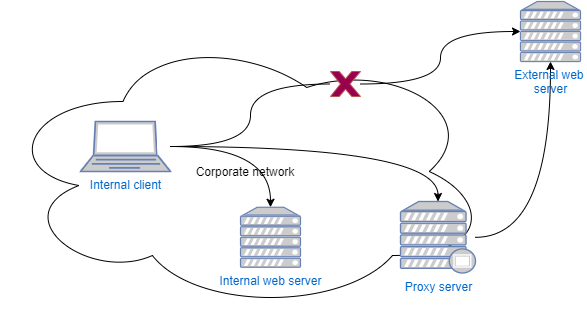
The internal client can access the internal web server directly without problems. However he cannot access the internet server directly so he needs to use the proxy to access it.
One thing that needs to be made crystal is that the fact that your browser works with the proxy does not mean that any other HTTP clients you use will also work. For example, you may want to run curl or wget to download some files from an external server; these programs will not work without setting a proxy (usually by setting the http_proxy and https_proxy environment variables or by passing a parameter). Also, the proxy only works for HTTP requests. If you are in a private network without external access you will not be able to access non-HTTP resources. For example you will not be able to access your non-company mail server (which uses either IMAP or POP3) from behind your company’s network. Typically, you’ll use a web client for accessing your mails.
So it seems that using a proxy heavily restricts the internal users usage of internet. What are the advantages of using a forward proxy?
- Security: Since the internal computers of a company will not have internet access there’s no easy way for attackers to access these computers.
- Content moderation: The company through the proxy can block access to various internet sites (i.e social network, gaming etc) that the users shouldn’t access during work.
- Caching: The proxy server can have a cache so when multiple users access the same internet resource it will downloaded only once saving the company’s bandwidth.
Especially the security thing is so important that almost all corporate (or university etc) networks will use a proxy server and never allow direct access to the internet.
A well known, open source forward proxy server is Squid.
Reverse proxy
A reverse proxy is an HTTP server that “proxies” (i.e forwards) some (or all) requests it receives to a different HTTP server and returns the answer back. For example, a company may have a couple of HTTP servers in its internal network. These servers have private addresses and cannot be accessed through the internet. To allow external users to access these servers, the company will configure a reverse proxy server that will forward the requests to the internal servers as seen in the picture:
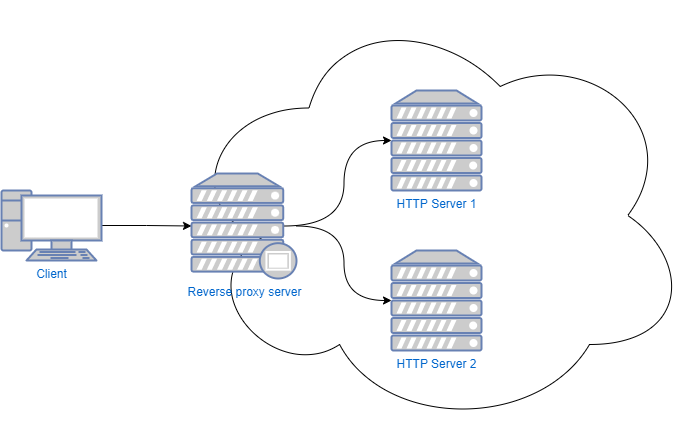
What happens is that the proxy server will forward requests that fulfill some specific criteria to other web servers. The criteria may be requests that have * a specific host (forward the requests that have a hostname of www.server1.company.com to the internal server named server1 and www.server2.company.com to the internal server named server2) * or a specific port (forward requests in the port 81 to server1 and requests in the port 82 to server2) * or even a particular path (forward requests with the path www.company.com/server1 to server1 and requests with the path www.company.com/server2 to server2)
or even other criteria that may be decided.
Let’s see some example of reverse proxying:
- A characteristic example of reverse proxy is the well-known 3-tier architecture (web server / app server / database server). The web server is used to serve all requests but it “proxies” (forwards) some of the requests to the app server. This is used because the web server cannot serve dynamic replies but can serve static replies like for example files.
- Offloading the SSL (https) security to a particular web server. This server will store the private key of your certificate and terminate the SSL connections. It will then forward the requests to the internal web servers using plain HTTP.
- An HTTP load balancer will proxy the requests to a set of other servers based on some algorithm to share the load (i.e the HAProxy software load balancer or even a hardware load balancer)
- A reverse proxy can be used to act as a security and DOS “shield” for your web servers. It will check the requests for common attack patterns and forward them to your servers only if they are safe
- A reverse proxy can be used for caching; it will return cached versions of resources if they are available to avoid overloading the application servers
- A CDN (content delivery network) is more or less a set of glorified reverse proxy servers that act as a first step for serving the user’s requests (based on the geographic location) also offering security protection and caching (this is what akamai or cloudflare do)
As can be seen from the previous examples there are a lot of apps that do reverse proxying, for example apache HTTP, nginx, HAProxy, varnish cache et al.
Notice that while there’s only one forward proxy, there could be a (large) chain of reverse proxies when accessing a remote server. Let’s take a look at a rather complex scenario: A user in a corporate network will access an application in another network. In this case the user’s request may pass through:
forward proxy (squid) -> security server / CDN (akamai) -> ssl termination (nginx) -> caching (varnish) -> web server (nginx again) -> app server (tomcat or gunicorn or IIS etc) as can be seen on the following image:
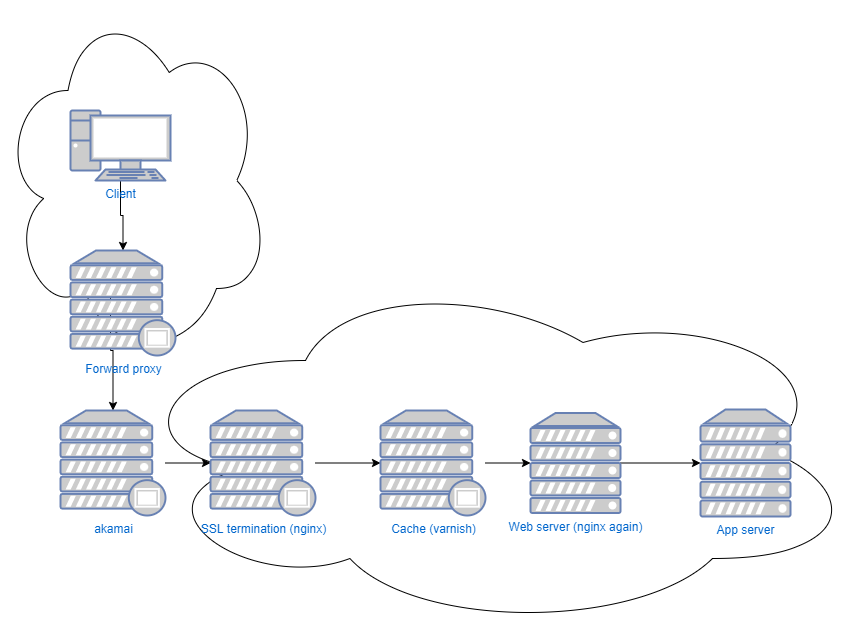
Notice that is this case (which is not uncommon) there are six (05) servers between your client and the application server!
One common problem with this is that unless all the intermediate servers are configured properly (by properly modifying and passing the X-Forwarded-For header) you won’t be able to retrieve the IP of the user that did the initial request.