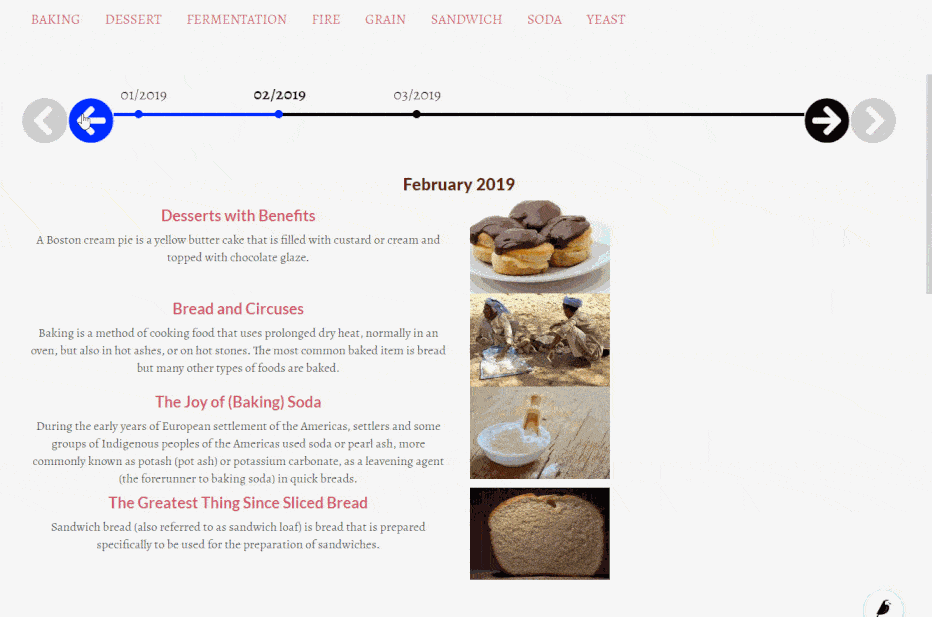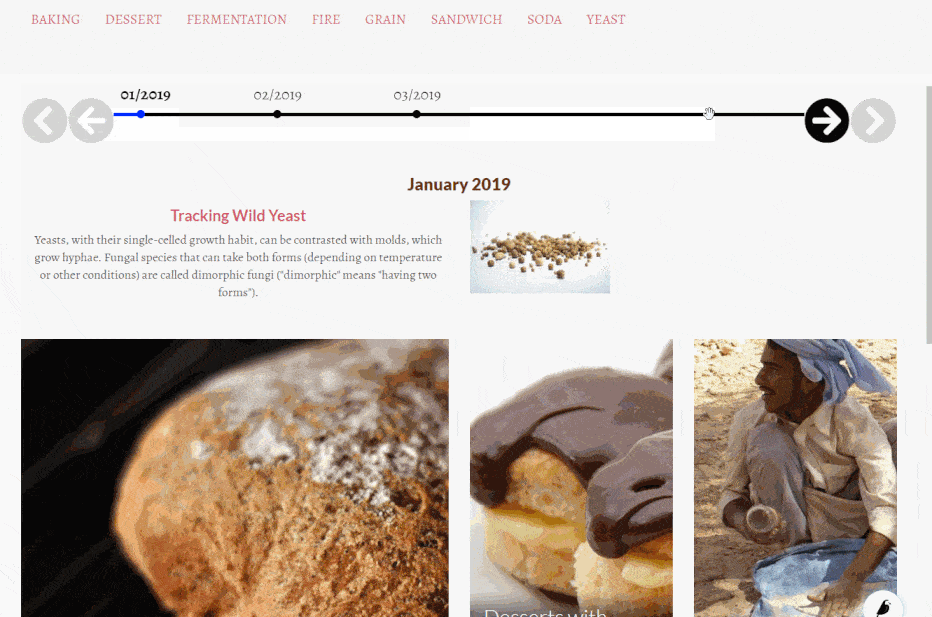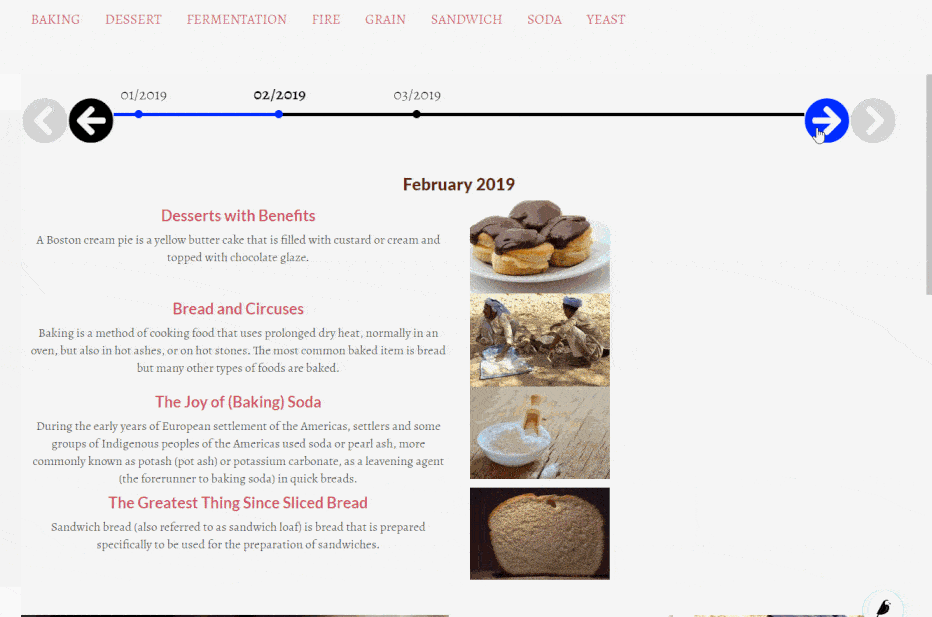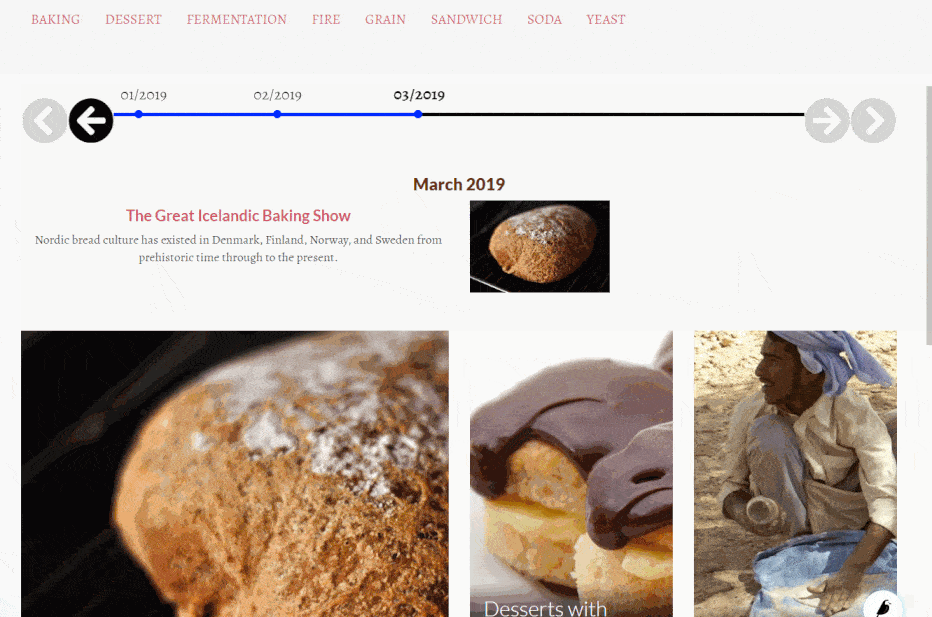
One common requirement I’ve seen in projects is that a model will start with a choices CharField but in the future this field will need to be converted to a normal foreign key to another model. This is such a common requirement that I’ve concluded that you need to double think before using choices because there’s a high possibility that in the lifetime of your project you’ll also need to convert it to a foreign key.
For example, let’s suppose you’ve got the following model:
CATEGORY_CHOICES = [
('cat1', 'Category 1 name',),
('cat2', 'Category 2 name',),
('cat3', 'Category 3 name',),
('cat4', 'Category 4 name',),
]
class Sample(models.Model):
name = models.CharField(max_length=100)
category = models.CharField(max_length=100, choices=CATEGORY_CHOICES)
You will need to convert it like this
class Category(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
class Sample(models.Model):
name = models.CharField(max_length=100)
category = models.ForeignKey('Category', on_delete=models.PROTECT)
There are various reasons that you may be forced to convert the choices field to a ForeignKey, some are:
- Your site administrators may need to sometime change these choices themselves
- You may want to add some properties to each choice i.e if a choice is active or not
- The choices info is local in your django project. If for some reason you want your data to be used by a different project (for example execute a reporing query directly from the database) you’ll just get the code for each choice (and not its name) leading you to ugly case statements in your queries to display the name of each choice. Furthermore, if the choices do change you’ll need to change them in two places (your django project and your reporting queries)
- The choice thing, although is very helpful and quick to implement leads to a non-normalized design. The name of each choice will be a string that would be duplicated to each row that has that particular choice.
In a previous article I had provided a recipe on how to properly normalize a database table containing a choices field like this using PL/pgSQL. This script should work in this case also but if you have a Django project then you should use migrations to do the conversion.
So let’s see how to convert our category choices field to a Foreign Key using django migrations!
The proper way to do it is in three distinct steps/migrations:
- Create the Category model and add a foreign key to it in the Sample model. You should not remove the existing choices field! So you’ll need to add another field to Sample for example named category_fk.
- Create a data migration to run a python script that will read the existing Sample instances and fill their category_fk field based on their category field.
- Remove the category field from Sample model and rename category_fk to category.
Let’s go through the steps one by one:
First we will change our initial models.py like this:
class Category(models.Model):
name = models.CharField(max_length=100)
class Sample(models.Model):
name = models.CharField(max_length=100)
category = models.CharField(max_length=100, choices=CATEGORY_CHOICES)
category_fk = models.ForeignKey('Category', on_delete=models.PROTECT, null=True)
So I’ve just added the Category model and the category_fk field to the Sample model. Notice the category choices field is still there since I need it to fill my category_fk! Also notice that I’ve added a null=True to the category_fk so it will allow the field to be added with a null value to the existing. I will fix that later. We can create and run an automatic migration now:
C:\progr\py3\migrations_tutorial>python manage.py makemigrations
Migrations for 'core':
core\migrations\0002_auto_20210715_0836.py
- Create model Category
- Add field category_fk to sample
C:\progr\py3\migrations_tutorial>python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, core, sessions
Running migrations:
Applying core.0002_auto_20210715_0836... OK
So now all my rows have an empty category_fk field.
For the second step, we will create the data migration that will fill the category_fk field. First of all let’s create an empty migration (notice my app is called core):
C:\progr\py3\migrations_tutorial>python manage.py makemigrations --empty core Migrations for 'core': core\migrations\0003_auto_20210715_0844.py
Let’s take a look at what Django has created for us:
from django.db import migrations
class Migration(migrations.Migration):
dependencies = [
('core', '0002_auto_20210715_0836'),
]
operations = [
]
This is an empty migration file, it just says that it will be run after the previous migration we just created. We’ll need to add an operation to it that will do the needed work of filling the category_fk field.
This can be done like this:
from django.db import migrations
def fill_category_fk(apps, schema_editor):
Sample = apps.get_model('core', 'Sample')
Category = apps.get_model('core', 'Category')
for sample in Sample.objects.all():
sample.category_fk, created = Category.objects.get_or_create(name=sample.category)
sample.save()
class Migration(migrations.Migration):
dependencies = [
('core', '0002_auto_20210715_0836'),
]
operations = [
migrations.RunPython(fill_category_fk),
]
The above should be straight forward. The only thing to notice is that you should use migrations.RunPython to declare that the migration will need to run some python code. Notice that RunPython takes a second parameter with another function which will be run during the backwards migration. In our case we don’t really need it, since we omit it, it will throw an error if you try to apply this migration backwards.
The fill_category_fk uses the apps.get_model function to have access to the models it needs. You should use this instead of importing the models directly because the current state of the database models may not be the same as the state that the migration expects. I’m just using get_or_create to insert or retrieve the proper Category instance (remember that get_or_create returns an (instance, created) tuple so we need to use the first element).
Now we can try running the migration:
C:\progr\py3\migrations_tutorial>python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, core, sessions
Running migrations:
Applying core.0003_auto_20210715_0844... OK
If any errors happened you will see the stack trace here and you will need to fix them. Don’t worry, the state of your database will not be changed until the migration finishes.
Now our database has both the (old) category and the (new) category_fk fields. Each will have the same value!
Now we need to remove the old category field and rename the existing category_fk. Let’s do it!
class Sample(models.Model):
name = models.CharField(max_length=100)
category = models.ForeignKey('Category', on_delete=models.PROTECT, null=True)
def __str__(self):
return self.name
And run the migration:
C:\progr\py3\migrations_tutorial>python manage.py makemigrations
Migrations for 'core':
core\migrations\0004_auto_20210715_0909.py
- Remove field category_fk from sample
- Alter field category on sample
Uh oh! This does not seem to do what I want. Let’s take a peek at the generated migration file:
class Migration(migrations.Migration):
dependencies = [
('core', '0003_auto_20210715_0844'),
]
operations = [
migrations.RemoveField(
model_name='sample',
name='category_fk',
),
migrations.AlterField(
model_name='sample',
name='category',
field=models.ForeignKey(null=True, on_delete=django.db.models.deletion.PROTECT, to='core.Category'),
),
]
This will remove the category_fk field we just filled from our model and then try to convert the old category field to a foreign key! If you try to run the migration you’ll get an exception because the existing category field cannot be converted to a ForeignKey!
It seems that Django migrations isn’t so smart after all… To resolve that we could just create two separate migrations: One to remove the old category field and the other to rename the category_fk field to category. Django would know then that we have renamed the category_fk field. This method works fine but if you are using category in your admin (or forms) django will complain with errors like this:
<class 'core.admin.SampleAdmin'>: (admin.E108) The value of 'list_display[1]' refers to 'category', which is not a callable, an attribute of 'SampleAdmin', or an attribute or method on 'core.Sample'.
So you’ll need to rename to fix this before running the migration (and if you actually fix it you may just bite the bullet and use category_fk to avoid re-renaming it back to category).
This is rather a pain so I’ll give you another way: Edit the created migration file to do exactly what you need, i.e remove the existing category field and rename category_fk to category. Here’s the migration file:
class Migration(migrations.Migration):
dependencies = [
('core', '0003_auto_20210715_0844'),
]
operations = [
migrations.RemoveField(
model_name='sample',
name='category',
),
migrations.RenameField(
model_name='sample',
old_name='category_fk',
new_name='category',
),
]
So in this migration we first remove the existing category field and then we rename the category_fk field to category. Let’s try to run it:
C:\progr\py3\migrations_tutorial>python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, core, sessions Running migrations: Applying core.0004_auto_20210715_0909... OK
Success!